(MLSAM was originally named MLSQL. If you are looking for how to write SQL queries against data stored in MarkLogic, please see the SQL Modeling Guide.)
MLSAM is an open source XQuery library (written by Jason Hunter of MarkLogic and Ryan Grimm of O'Reilly Media) that allows easy access to relational database systems from within the MarkLogic environment. MLSAM lets you execute arbitrary SQL commands against any relational database (MySQL, Oracle, DB2, etc) and it captures the results as XML for processing within the MarkLogic environment. Using the library enables XQuery applications to leverage a relational database without having to resort to Java or C# glue code to manage the interaction.This article introduces MLSAM, its architecture and API, and demonstrates a few real life applications built on the library.
Architecture
MLSAM consists of a couple hundred lines of XQuery and a few hundred lines of Java servlet code. The XQuery uses xdmp:http-post() to send the SQL query to the servlet, and the servlet uses JDBC to pass the query to the relational database. Any database with JDBC support will do. The servlet then returns the result set or update details as XML over the wire to the XQuery environment.
The servlet holds the database credentials, connection details, and manages a connection pool for efficiency. The XQuery can pass "bind parameters" to the database as part of the query for efficiency and safety. The diagram below shows the architecture.

Installation and configuration details follow at the end of this article.
Credentials and Security
For simplicity in MLSAM 1.0 we've opted to encapsulate the database details inside the servlet. An alternate design would allow the XQuery to pass the details, such as in the query string. If you're interested in this, talk to us. Note that for database security, you should restrict access to the MLSAM web service to only the trusted MarkLogic host. Tools like tcpwrappers makes this easy.
Basic Usage
The following code demonstrates how to execute a SQL query from within a MarkLogic XQuery environment. For our first set of queries we'll assume a MySQL back-end that has a clickstream table for tracking search requests (who requested what, when, and how many results they saw). Let's start by executing a query to learn about the table:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("select * from clickstream limit 2",
"http://localhost:8080/mlsql", ())
The sql:execute() method from the sql.xqy library module accepts three arguments: the SQL query, the URL of the servlet supporting the library, and an optional options node containing bind parameters and other options. The query returns a <sql:result> root element holding a <sql:meta> providing metadata (exceptions, warnings, update counts, auto-generated keys, etc), and a series of <sql:tuple> elements representing each row of the result set:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<id>1</id>
<issued>2006-03-21 00:59:42.0</issued>
<page>1</page>
<results>170</results>
<query>java and xml</query>
<user>172.17.146.37</user>
</sql:tuple>
<sql:tuple>
<id>2</id>
<issued>2006-03-21 01:01:33.0</issued>
<page>1</page>
<results>195</results>
<query>xquery</query>
<user>172.17.146.37</user>
</sql:tuple>
</sql:result>
Each <sql:tuple> holds elements representing the columns of each row. The names are provided by the table, by default. Now let's ask MySQL to describe the table, so we can learn about its types:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("describe clickstream",
"http://localhost:8080/mlsql", ())
Now, if you were to write the query describe clickstream into the "mysql" command-line tool you would see this text representation of the result:
+---------+--------------+------+-----+-------------------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+-------------------+----------------+ | id | int(11) | | PRI | NULL | auto_increment | | issued | timestamp | YES | | CURRENT_TIMESTAMP | | | page | int(11) | YES | | NULL | | | results | int(11) | YES | | NULL | | | query | varchar(255) | YES | | NULL | | | user | varchar(50) | YES | | NULL | | +---------+--------------+------+-----+-------------------+----------------+
By querying with MLSAM the result takes on an XML form:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<Field>id</Field>
<Type>int(11)</Type>
<Null/>
<Key>PRI</Key>
<Default null="true"/>
<Extra>auto_increment</Extra>
</sql:tuple>
<sql:tuple>
<Field>issued</Field>
<Type>timestamp</Type>
<Null>YES</Null>
<Key/>
<Default>CURRENT_TIMESTAMP</Default>
<Extra/>
</sql:tuple>
<sql:tuple>
<Field>query</Field>
<Type>varchar(255)</Type>
<Null>YES</Null>
<Key/>
<Default null="true"/>
<Extra/>
</sql:tuple>
<sql:tuple>
<Field>results</Field>
<Type>int(11)</Type>
<Null>YES</Null>
<Key/>
<Default null="true"/>
<Extra/>
</sql:tuple>
<sql:tuple>
<Field>page</Field>
<Type>int(11)</Type>
<Null>YES</Null>
<Key/>
<Default null="true"/>
<Extra/>
</sql:tuple>
<sql:tuple>
<Field>user</Field>
<Type>varchar(50)</Type>
<Null>YES</Null>
<Key/>
<Default null="true"/>
<Extra/>
</sql:tuple>
</sql:result>
That's a lot of data. We can simplify the report by processing the answers using XPath. For example:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("describe clickstream",
"http://localhost:8080/mlsql", ())
//Field
This returns:
<Field>id</Field> <Field>issued</Field> <Field>query</Field> <Field>results</Field> <Field>page</Field> <Field>user</Field>
Now that we understand our table structure, we can issue a useful select. Let's see what queries had an estimate hit count above 10,000:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("select distinct query from clickstream
where results > 10000",
"http://localhost:8080/mlsql", ())
This returns:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<query>web</query>
</sql:tuple>
<sql:tuple>
<query>make</query>
</sql:tuple>
</sql:result>
We can add the XPath //query/text() to the call to obtain just the words:
web make
Bind Variables
The third argument to sql:execute() is an XML options node that can include various things including a list of bind parameter values. We can rewrite the query above to use a bind parameter. This tends to help database performance (as databases can cache previously generated query plans) and security (as bind parameters prevent SQL injection attacks).
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("select distinct query from clickstream
where results > ?",
"http://localhost:8080/mlsql", sql:params(10000))
//query/text()
The sql:params() convenience function introspects the sequence of atomics passed to it and returns a <sql:execute-options> node. For the curious, here's the actual XML passed as the third argument above (which thanks to sql:params() you'll practically never have to write):
<sql:execute-options xmlns:sql="http://xqdev.com/sql">
<sql:parameters>
<sql:parameter type="int">10000</sql:parameter>
</sql:parameters>
</sql:execute-options>
The sql:params() call sets the types attribute based on the type of the atomic passed in. If you pass "1" instead of 1 the XML will say type="string" and the servlet's JDBC call will know to set the value using setString(). (The one situation where you may have to write this XML explicitly is when passing a null bind parameter, as it's hard to represent a null in an XQuery sequence. See the wire protocol section at the bottom for details on passing a null.)
The following example shows a query that makes heavy use of bind parameters to insert a new search into the clickstream table. This query is one that might appear in a search.xqy library. It checks the XML returned in order to log any exceptions:
let $status := sql:execute("
insert into clickstream (query, page, results, user) values (?, ?, ?, ?)
",
"http://localhost:8080/mlsql", sql:params(($query, $page, $est, $ip)))
return
if (exists($status//sql:exception))
then xdmp:log($status, "warning")
else ()
What XML does an insert return? It also returns a <sql:result> but places into the meta section the number of rows updated and any auto-generated key (such as the id from the new row):
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta>
<sql:rows-affected>1</sql:rows-affected>
<sql:generated-key>746</sql:generated-key>
</sql:meta>
</sql:result>
Of course, our query above discards this XML after checking it for exceptions. If there had been an exception returned, the XML would look something like this:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta>
<sql:exceptions>
<sql:exception type="java.sql.SQLException">
<sql:reason>You have an error in your SQL syntax; check the manual
that corresponds to your MySQL server version for the right
syntax to use near 's ('z ebra', 1, 1, '127.0.0.1')'
at line 1</sql:reason>
<sql:sql-state>42000</sql:sql-state>
<sql:vendor-code>1064</sql:vendor-code>
</sql:exception>
</sql:exceptions>
</sql:meta>
</sql:result>
It's wise to check for <sql:exception> elements after each sql:execute() call. Sometimes you'll have more than one. You can also check for <sql:warning> elements.
Should sql:execute() throw an error?
An alternate design would have sql:execute() throw an XQuery error() if any exception occurs. We've opted not to do this in MLSAM 1.0 because the error() function atomizes its parameter, turning a node containing <sql:exception> instances into a simple concatenated string made up of their text values. We could work around this by doing an xdmp:quote() on the exception hierarchy and expecting any catch clause to xdmp:unquote() as part of the catch, an option we're investigating.
Using the Clickstream
Now that we're tracking search requests in the "clickstream" table, we can enable some search hinting similar to Google Suggest. Here's how that would look (using the open source project LiveSearch):
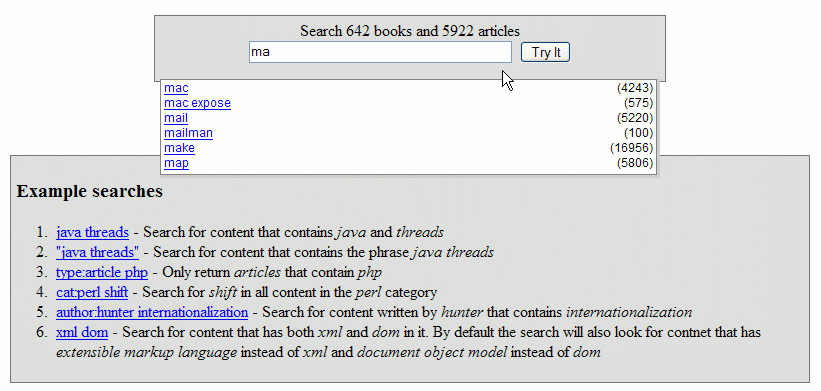
(Click on the image for a larger view)
Every keypress in the search box triggers an XMLHttpRequest call to the server, passing the typed text and accepting back the top 10 most common searches beginning with that prefix (as well as their result count). The following suggest.xqy main module could be the target of the XMLHttpRequest:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
default function namespace = "http://www.w3.org/2003/05/xpath-functions"
let $prefix := xdmp:get-request-field("prefix")
return
sql:execute("
select * from (
select query, max(results) as results, count(*) as times
from clickstream
where query like ?
and results > 0
group by query
order by times desc
limit 10
) x
order by query
", "http://localhost:8080/mlsql", sql:params(concat($prefix, '%')))
It alphabetizes the results from an inner select which selects the 10 most popular queries with that prefix. Note this query uses a few MySQL features that won't be available on other engines. Also note that this query is quite simplistic and wouldn't scale to a large number of rows. For real use you'd need to generate and manage summarization tables. It returns answers like this after the user types "x":
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<query>x11</query>
<results>468</results>
<times>7</times>
</sql:tuple>
<sql:tuple>
<query>xlib</query>
<results>23</results>
<times>2</times>
</sql:tuple>
<sql:tuple>
<query>xm radio</query>
<results>21</results>
<times>14</times>
</sql:tuple>
<sql:tuple>
<query>xml</query>
<results>5712</results>
<times>9</times>
</sql:tuple>
<sql:tuple>
<query>xml dom</query>
<results>954</results>
<times>9</times>
</sql:tuple>
<!-- etc -->
</sql:result>
To hook into LiveSearch these hits have to be massaged into an HTML format, but that's easy using XQuery.
Use Case: Leveraging a Spatial Index
Spatial indexes (implemented using R-trees) enable fast queries based on 2D position information. They let you find all entries within some distance of a point, contained within an arbitrary polygon, and so on. It's a type of index not yet supported in MarkLogic, but recently supported in MySQL. By using MLSAM to connect to MySQL we can access spatial indexes within MarkLogic.
[UPDATE: In the time since this article was written, MarkLogic has added rich built-in support for geospatial indexes.]
To demonstrate spatial indexing, we'll query against a free zipcode database that's included with the MLSAM distribution. You can load the table data with the following command:
mysql -u youruser -p yourdb < zipcodes.sql
Once it's loaded, you can use the following query to list the fields in the zipcodes table:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("describe zipcodes", "http://localhost:8080/mlsql", ())
//Field/text()
It reports the table has six columns with these names:
zipcode state city latitude longitude geo
Let's select a row:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
default function namespace = "http://www.w3.org/2003/05/xpath-functions"
sql:execute("
select zipcode, city, state, AsText(geo) as geo
from zipcodes
where zipcode = ?",
"http://localhost:8080/mlsql", sql:params(95070))
This returns:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<zipcode>95070</zipcode>
<city>Saratoga</city>
<state>CA</state>
<geo>POINT(37.253922 -122.063797)</geo>
</sql:tuple>
</sql:result>
Notice the "as geo" part of the query. This gives a name to the text representation of the geospatial column. Without that addition you get this error:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta>
<sql:exceptions>
<sql:exception type="org.jdom.IllegalNameException">
<sql:reason>The name "AsText(geo)" is not legal for
JDOM/XML elements: XML names cannot contain the
character "(".</sql:reason>
</sql:exception>
</sql:exceptions>
</sql:meta>
</sql:result>
MLSAM uses the column name chosen by the database as the XML element name. If you don't like the name, or if it's an illegal name like above, you can use the "as newname" feature to rename the column from within SQL.
What about null columns? They have a null attribute to differentiate them from an empty string. For example:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<name>Barney</name>
<age null="true"/>
</sql:tuple>
</sql:result>
Along with the MLSAM distribution you'll find a zipcodes.xqy library module. It leverages the sql.xqy module and the free zipcodes table data to implement a zip:within() function. This call returns all zip codes within a certain number of miles from another, based on a great circle polygon. If you're interested in the math you can look at the zipcodes.xqy source code, but here's the simple usage:
import module namespace zip =
"http://xqdev.com/zipcodes" at "zipcodes.xqy"
zip:within("95070", 4.5)
This query returns:
<area> <zipcode>95070</zipcode> <city>Saratoga</city> <state>CA</state> <distance>0.0</distance> </area> <area> <zipcode>95014</zipcode> <city>Cupertino</city> <state>CA</state> <distance>3.87</distance> </area> <area> <zipcode>95030</zipcode> <city>Los Gatos</city> <state>CA</state> <distance>4.45</distance> </area>
The xdmp:query-meters() call shows this query executing in 0.03 seconds. Given that speed, it won't take long to forget it's relational backed.
Performance
In simple testing on a laptop, the MLSAM servlet was able to push about 1,000 simple tuples per second toward the client. We anticipate that's fast enough for most SQL queries you will write from XQuery. Just don't try to pull a whole table into the XQuery environment and process it with XPath. That's why SQL has WHERE clauses.
What's zip:within() good for? Let's assume you have documents or elements in MarkLogic coded by zipcode (like yellow page entries). To search entries within 5 miles of a home zipcode, you can use this query to get the list of zipcodes to include in the search. You could even implement a dynamic thesaurus to treat nearby zip codes as synonyms.
Or let's assume you have documents containing geographic coordinates, like a location of origin. Their URIs could be stored in MySQL rows along with the POINT data. A quick query like this could return all the URIs with points matching a geographic polygon. That sequence of URIs then could be passed into MarkLogic's doc() call to limit the scope of a larger search.
Bottom line: MLSAM makes it easy to mix and match MarkLogic and relational database queries within the XQuery environment, enabling you to take advantage of each platform as appropriate.
Installation
Installing MLSAM requires a few simple steps:
First, expose the sql.xqy library module to your XQuery code. This usually requires copying the file into your HTTP server root directory, but depending on configuration might require loading into the server's modules database.
Second, install the servlet code. The distribution includes a build directory containing the web application root. Copy this to your servlet engine's webapps directory or adjust the server's configuration to point at the directory as a web application root. (If you don't have a servlet engine, Jetty is an free server that's easy to install and configure.)
Third, provide database credentials and connection details. The web application includes a web.xml file with init parameters the servlet will read in order to connect to the database. Adjust these as appropriate for your system. You'll need to set the JDBC driver, connection URL, username, and password. The web.xml file includes instructions.
Fourth, make sure to add your JDBC driver JAR files to the WEB-INF/lib directory. Driver libraries aren't usually licensed for redistribution, so you'll have to obtain them on your own.
Fifth, test the servlet's URL. Try making a basic web request to the MLSAM servlet. You'll know it's listening and you've found it when you get a <sql:exception> talking about "Premature end of file". That means you didn't provide a query, but at least you found the servlet.
Sixth, test the XQuery connecton. Write a basic query like this:
import module namespace sql = "http://xqdev.com/sql" at "sql.xqy"
sql:execute("select 1 as test", "http://localhost:8080/mlsql", ())
You might need to adjust the "at" depending on where you placed the library module. If it works you'll see this result:
<sql:result xml:lang="en" xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<test>1</test>
</sql:tuple>
</sql:result>
Now have fun!
[UPDATE: The MLSAM 1.1 release adds a sql:executeProcedure() call that supports OUT and INOUT parameters. These details are not documented here.]
Appendix: Protocol Details
This section describes the wire protocol between the client and server. They're documented here for completeness and to aid the project's ongoing development.
The client POSTs a request to the Java servlet containing an XML document that follows the simple format defined by this Relax NG Compact schema:
namespace sql="http://xqdev.com/sql"
element sql:request {
element sql:type { "select"|"update"|"execute" },
element sql:query { text },
element sql:execute-options {
element sql:max-rows { xsd:integer }? &
element sql:query-timeout { xsd:integer }? &
element sql:max-field-size { xsd:integer }? &
element sql:parameters {
element sql:parameter {
attribute type { "int"|"string"|"boolean"|"date"|"double"|
"float"|"short"|"time"|"timestamp" },
attribute null { "true" }?,
text
}+
}?
}
}
An instance of a request thus looks like this:
<sql:request xmlns:sql="http://xqdev.com/sql">
<sql:type>execute</sql:type>
<sql:query>select * from user
where id = ? and name = ? and location is ?</sql:query>
<sql:execute-options>
<sql:max-rows>10</sql:max-rows>
<sql:query-timeout>10</sql:query-timeout>
<sql:max-field-size>10</sql:max-field-size>
<sql:parameters>
<sql:parameter type="int">10</sql:parameter>
<sql:parameter type="string">Caesar</sql:parameter>
<sql:parameter type="string" null="true"></sql:parameter>
</sql:parameters>
</sql:execute-options>
</sql:request>
The servlet returns a response conforming to this Relax NG Compact schema:
namespace sql="http://xqdev.com/sql"
element sql:result {
(
# update
# a meta with rows affected, any generated key, possible warnings
element sql:meta {
element sql:rows-affected { xsd:integer } &
element sql:generated-key { text }? &
element sql:warnings {
element sql:warning {
attribute type { text }?,
element sql:reason { text },
element sql:sql-state { text },
element sql:vendor-code { text }
}+
}?
}
) |
(
# select
# has a series of tuples of any set of elements, possible warnings
element sql:meta {
element sql:warnings {
element sql:warning {
attribute type { text }?,
element sql:reason { text },
element sql:sql-state { text },
element sql:vendor-code { text }
}+
}?
},
element sql:tuple {
element * {
attribute null { "true" }?,
text
}+
}*
) |
(
# error
# has just a meta, one or more exceptions, any number of warnings
element sql:meta {
element sql:exceptions {
element sql:exception {
attribute type { text }?,
element sql:reason { text },
element sql:sql-state { text },
element sql:vendor-code { text }
}+
}+,
element sql:warnings {
element sql:warning {
attribute type { text }?,
element sql:reason { text },
element sql:sql-state { text },
element sql:vendor-code { text }
}+
}?
}
)
}
The responses can be separated into three types, depending if the request was an update or select, or generated errors. Here's an example response to an update:
<sql:result xmlns:sql="http://xqdev.com/sql">
<sql:meta>
<sql:rows-affected>1</sql:rows-affected>
<sql:generated-key>746</sql:generated-key>
</sql:meta>
</sql:result>
Here's an example response to a select:
<sql:result xmlns:sql="http://xqdev.com/sql">
<sql:meta/>
<sql:tuple>
<id>1</id>
<fname>Jason</fname>
<lname>Hunter</lname>
<age>32</age>
</sql:tuple>
<sql:tuple>
<id>1235</id>
<fname>Ryan</fname>
<lname>Grimm</lname>
<age null="true"></age>
</sql:tuple>
</sql:result>
Finally, here's an example response that includes an error:
<sql:result xmlns:sql="http://xqdev.com/sql">
<sql:meta>
<sql:exceptions>
<sql:exception type="java.sql.SQLException">
<sql:reason>Table 'x' doesn't exist</sql:reason>
<sql:sql-state>42S02</sql:sql-state>
<sql:vendor-code>1146</sql:vendor-code>
</sql:exception>
</sql:exceptions>
</sql:meta>
</sql:result>