MLJAM is an open source XQuery and Java library (written by Jason Hunter of MarkLogic and Ryan Grimm of O'Reilly Media, the same pair behind MLSQL) that enables the evaluation of Java code from the MarkLogic Server environment. Put simply, it's a Java Access Module. MLJAM gives XQuery programs access to the vast libraries and extensive capabilities of Java, without any difficult glue coding. Example uses for MLJAM:
- Extracting image metadata
- Resizing and reformatting an image
- Running an XSLT transformation [available natively in MarkLogic since version 5.0]
- Generating a PDF from XSL-FO
- Calculating an MD5 hash [available natively in MarkLogic since version 5.0]
- Interfacing into a user authentication system
- Accessing a credit card purchasing system
- Connecting to a secure HTTPS web site
- Re-encoding content as UTF-8
To demonstrate what MLJAM code looks like, here's an XQuery function that returns the MD5 hash of a passed-in string, built using MLJAM to access Java's MessageDigest class:
Editor's Note: MarkLogic added a function to compute MD5 hashes in MarkLogic 5. Wouldn't you rather use something like sha-512 anyway?
(: Assume start() and end() are called externally :)
define function md5($x as xs:string) as xs:string
{
jam:set("md5src", $x),
jam:eval('
import java.security.MessageDigest;
digest = MessageDigest.getInstance("MD5");
md5hash = digest.digest(md5src.getBytes("UTF-8"));
'),
xs:string(jam:get("md5hash"))
}
The first line creates a Java variable "md5src" and assigns it a value based on the $x variable in XQuery. The second line executes a bit of Java code to calculate the MD5 hash of the string. The last line retrieves the hashed value and returns it as a string.
Where does the Java actually run? And since when can you assign a Java variable without a type declaration, or do a class import right inline? How efficient is all this? What does it mean for XQuery program architectures?
We'll address each of these questions, and more, in this tutorial.
Architecture
To begin with, the Java code does not run within the MarkLogic Server process. It runs in a separate Java servlet engine process, probably on the same machine as MarkLogic but not necessarily.
The MLJAM distribution contains two halves: an XQuery library module (about 400 lines of code) and a custom Java servlet (about 700 lines of code). The XQuery makes xdmp:http-get() and xdmp:http-post() calls to the servlet to drive the interaction between the two languages. The wire protocol uses a simple REST-based web services architecture. It's discussed in detail at the end of the article.
Some might think it difficult or impossible to execute arbitrary Java code snippets based on a string that's passed to a servlet, but it's not difficult at all thanks to the open source BeanShell library. Per http://www.beanshell.org/intro.html:
"BeanShell is a small, free, embeddable Java source interpreter with object scripting language features, written in Java. BeanShell dynamically executes standard Java syntax and extends it with common scripting conveniences such as loose types, commands, and method closures like those in Perl and JavaScript."
BeanShell acts as the mind and muscle within the servlet. BeanShell exposes Interpreter objects -- each of which has set(), eval(), and get() methods that behind the scenes the earlier code utilized. By default, each XQuery client has its own BeanShell Interpreter instance (a little Java universe) all to itself. If desired, several XQuery clients can share the same Interpreter.
BeanShell makes it easy to execute Java code as simple as the expression 1+1 or as complicated as a multi-class program. For more information on the BeanShell and its features, see http://www.beanshell.org/docs.html.
Putting it all together, the architecture looks like this:
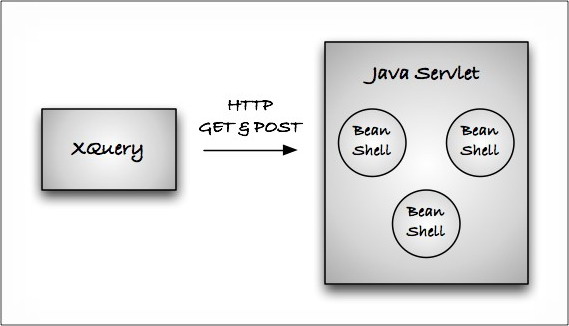
Installation and configuration details follow at the end of this article.
Basic Function Overview
The jam.xqy library module exposes the following functions:
- jam:start($url as xs:string, $user as xs:string?, $pass as xs:string?) as empty()
- jam:set($var as xs:string, $value as item()*) as empty()
- jam:set-array($var as xs:string, $value as item()*) as empty()
- jam:eval($expr as xs:string) as empty()
- jam:get($var as xs:string) as item()*
- jam:eval-get($expr as xs:string) as item()*
- jam:unset($var as xs:string) as empty()
- jam:get-stdout() as xs:string
- jam:get-stderr() as xs:string
- jam:source($bsh as xs:string) as empty()
- jam:end() as empty()
The jam:start() and jam:end() bookend all MLJAM interaction. The jam:start() function specifies the web address of the MLJAM servlet (and optionally any required Java server authentication credentials). The jam:end() tells the servlet it's OK to destroy the Interpreter for this client.
The jam:set(), jam:set-array(), jam:get(), and jam:unset() calls marshall variables back and forth. The jam:eval() function executes the passed-in Java code, returning empty(), and jam:eval-get() does the same except returns the value of the last executed statement.
The jam:get-stdout() and jam:get-stderr() functions return the captured standard out and standard error from the Java context. The jam:source() function loads BeanShell script code from the named file.
Sharing a Long-Running Context
Each function listed above actually has an alternate form, one that adds -in to the name and accepts an extra context id parameter. You use the alternate form of a function when you want to execute in a specific named context (i.e. when wanting to share a context between queries). By default execution happens in a context with a random context id, isolated to just the running query. Here are the alternate forms:
- jam:start-in($url as xs:string, $user as xs:string?, $pass as xs:string?, $cid as xs:string) as empty()
- jam:set-in($var as xs:string, $value as item()*, $cid as xs:string) as empty()
- jam:set-array-in($var as xs:string, $value as item()*, $cid as xs:string) as empty()
- jam:eval-in($expr as xs:string, $cid as xs:string) as empty()
- jam:get-in($var as xs:string, $cid as xs:string) as item()*
- jam:eval-get-in($expr as xs:string, $cid as xs:string) as item()*
- jam:unset-in($var as xs:string, $cid as xs:string) as empty()
- jam:get-stdout-in($cid as xs:string) as xs:string
- jam:get-stderr-in($cid as xs:string) as xs:string
- jam:source-in($bsh as xs:string, $cid as xs:string) as empty()
- jam:end-in($cid as xs:string) as empty()
The naming convention follows that of xdmp:eval() and its alternate form xdmp:eval-in(). Now let's look at each function in depth.
Function Reference
jam:start() & jam:start-in()
The jam:start() function specifies the web address where the MLJAM servlet can be found and the credentials for access. You can pass () for the user and password fields if the Java server doesn't require authentication (a bit of a risky proposition for a service executing arbitrary code). For example:
jam:start("http://localhost:8080/mljam", "myuser", "mypass")
The function doesn't connect to the remote server, it just alters the query's internal state to remember the given facts. If you forget to call jam:start() then the first MLJAM function that actually does connect over the wire will generate an error.
The alternate form, jam:start-in() accepts a context id. For example:
jam:start-in("http://localhost:8080/mljam", "mljam", "secret", "local"),
jam:start-in("http://remotehost:8080/mljam", "mljam", "hidden", "remote")
This call creates a mapping between a web address and a context id. Later calls made using either context id can be routed to the appropriate web service. As shown above, it's simple for the same XQuery to connect to any number of different servers and/or to any number of individual contexts on a server.
jam:set() & jam:set-in()
The jam:set() function assigns a variable in the remote Java context. For example:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:set("x", 5),
jam:end()
XQuery types are mapped to Java types according to the following table (setting other type generates an error):
| XQuery Type | Java Type |
|---|---|
| xs:anyURI | String |
| xs:base64Binary | byte[] |
| xs:boolean | boolean |
| xs:date | javax.xml.datatype.XMLGregorianCalendar |
| xs:dateTime | javax.xml.datatype.XMLGregorianCalendar |
| xs:decimal | BigDecimal |
| xs:double | double |
| xs:duration | javax.xml.datatype.Duration |
| xs:float | float |
| xs:gDay | javax.xml.datatype.XMLGregorianCalendar |
| xs:gMonth | javax.xml.datatype.XMLGregorianCalendar |
| xs:gMonthDay | javax.xml.datatype.XMLGregorianCalendar |
| xs:gYear | javax.xml.datatype.XMLGregorianCalendar |
| xs:gYearMonth | javax.xml.datatype.XMLGregorianCalendar |
| xs:hexBinary | byte[] |
| xs:int | int |
| xs:integer | long |
| xs:QName | javax.xml.namespace.QName |
| xs:string | String |
| xs:time | javax.xml.datatype.XMLGregorianCalendar |
| xdt:dayTimeDuration | javax.xml.datatype.Duration |
| xdt:untypedAtomic | String |
| xdt:yearMonthDuration | javax.xml.datatype.Duration |
| attribute() | String holding its xdmp:quote() value |
| comment() | String holding its xdmp:quote() value |
| document-node() | String holding its xdmp:quote() value |
| element() | String holding its xdmp:quote() value |
| processing-instruction() | String holding its xdmp:quote() value |
| text() | String holding its xdmp:quote() value |
| binary() | byte[] |
| () | null |
If the XQuery $value holds a sequence of values, it's passed to Java as an Object[] array holding instances of the above types (with primitives autoboxed).
The mapping of node types is interesting. An XQuery element() appears in Java as a String holding serialized XML. This avoids the wasted effort of creating a JDOM or W3C DOM tree in Java when most likely the tree structure isn't needed. If you do need a tree, you can always build a JDOM or W3C DOM from a String (using a StringReader).
The alternate form jam:set-in() allows assignment in a specific context. For example:
jam:start-in("http://localhost:8080/mljam", "mljam", "secret", "local"),
jam:start-in("http://remotehost:8080/mljam", "mljam", "secret", "remote"),
jam:set-in("x", 5, "local")
(: No jam:end(), we assume the contexts should persist :)
Notice the use of commas to separate MLJAM function calls. That's the way in XQuery to evaluate a series of expressions. Don't use a semi-colon.
Advanced tip: If the XQuery $value holds a single value that's represented in Java as a String or byte[] then it can be sent on the wire in an optimized fashion.
jam:set-array() & jam:set-array-in()
These functions let you assign an XQuery value to a Java array, even if the value in XQuery is a single item. This is important because in XQuery there's no difference between a single item and a sequence of length one containing that item. So if you have an xs:string* type and want to pass it to Java as an array (even when it happens to be a single string), use these functions. Java will see the variable as an Object[].
jam:eval() & jam:eval-in()
The jam:eval() function makes the magic happen. It executes the given Java code in the remote context. The Java code can be anything that BeanShell can understand. The function always returns empty(), but leaves the state changed in the remote context. Here's a simple example:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:eval('x = -1; y = "two"; z = Math.sqrt(x);'),
jam:end()
At the end of the eval, the remote Java context has three new variables with values x=1, y="two", and z=NaN (not a number).
As you may recall, XQuery allows its strings to be surrounded by either single quotes or double quotes. When doing a jam:eval() it's often best to surround the Java code with single quotes. That way, Java can make free use of double quotes, and only the rare Java single quotes have to be escaped (by writing two single quotes in a row). It's also possible in XQuery to extend string literals across line breaks, so the above can be written more readably like this:
jam:eval('
x = 1;
y = "two";
z = Math.sqrt(x);
// Don''t forget single quote escaping
')
Variable scoping
Any variable created in a jam:eval() persists in the context for later retrieval. Normally you want this. However, when writing widely reusable library modules you risk introducing problems if any of your variable names collide with names used by other code executing in the same context (including your own library if in a shared context). You can limit variable scope by surrounding the evaluated code with curly braces. This creates a Java code block and, per the Java specification, any variable declarations within a code block aren't visible outside the block. But there's a catch: in BeanShell this rule only applies to standard Java variable declarations, those that include a type declaration. Variables declared without a type survive outside the code block.
Bottom line: If collisions concern you, use curly braces and specify the type for all your private variables. For example:
jam:eval('{ int x = 1; String y = "two"; double z = Math.sqrt(x); }')These variables all disappear right after the jam:eval() completes.
For more information: http://www.beanshell.org/manual/syntax.html#Basic_Scoping_of_Variables
The alternate form jam:eval-in() allows evaluation in a specific named context. For example:
jam:start-in("http://localhost:8080/mljam", "mljam", "secret", "local"),
jam:start-in("http://remotehost:8080/mljam", "mljam", "secret", "remote"),
jam:eval-in('1+1', "local")
jam:get() & jam:get-in()
The jam:get() function retrieves from the remote Java context the value of the named parameter. The following, for example, returns the number 5:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:set("x", 5),
jam:get("x"),
jam:end()
Java types are mapped to XQuery types according to the following table (getting any other type generates an error):
| Java Type | XQuery Type |
|---|---|
| byte[] | binary() |
| BigDecimal | xs:decimal |
| boolean | xs:boolean |
| double | xs:double |
| float | xs:float |
| int | xs:int |
| long | xs:integer |
| Date | xs:dateTime |
| String | xs:string |
| JDOM Attribute | attribute() |
| JDOM Comment | comment() |
| JDOM Document | document-node() |
| JDOM Element | element() |
| JDOM PI | processing-instruction() |
| JDOM Text | text() |
| XMLGregorianCalendar | xs:dateTime, xs:time, xs:date, xs:gYearmonth, xs:gMonthDay, xs:gYear, xs:gMonth, or xs:gDay depending on getXMLSchemaType() |
| Duration | xs:duration, xdt:dayTimeDuration, or xdt:yearMonthDuration depending on getXMLSchemaType() |
| QName | xs:QName |
| null | () |
If the Java variable holds an array, it's returned to XQuery as a sequence. Note the rule that JDOM node types are mapped to XQuery node types. This provides an easy way to build XML in Java for processing by XQuery.
It does however produce the oddity that an XQuery node passed to Java and back becomes an xs:string (element() -> String -> xs:string).
Advanced tip: If the Java variable holds a single String or byte[] it can be sent to XQuery on the wire in an optimized fashion (same as for jam:set()).
The alternate form jam:get-in() allows retrieval from a named context:
jam:start-in("http://localhost:8080/mljam", "mljam", "secret", "local"),
jam:start-in("http://remotehost:8080/mljam", "mljam", "secret", "remote"),
jam:set-in("x", 5, "remote"),
jam:get-in("x", "remote")
(: No jam:end(), assume the contexts should persist :)
jam:eval-get() & jam:eval-get-in()
The jam:eval-get() call combines evaluation with value retrieval to be more efficient on the wire -- accomplishing two tasks in one request. It returns the value of the last statement executed. For example:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:eval-get('System.getProperty("java.vm.version")'),
jam:end()
This call returns a value like "1.5.0". While this call:
jam:eval-get('x = 1; y = 2;')
Returns the number 2.
The alternate form jam:eval-get-in() does its work in the named context. The following code compares Java versions on the two machines (we assume a string comparison is good enough for Java version strings):
jam:start-in("http://localhost:8080/mljam", "mljam", "secret", "local"),
jam:start-in("http://remotehost:8080/mljam", "mljam", "secret", "remote"),
let $local :=
jam:eval-get-in('System.getProperty("java.vm.version")', "local")
let $remote :=
jam:eval-get-in('System.getProperty("java.vm.version")', "remote")
return
if ($local > $remote) then
concat("Local wins: ", $local)
else
concat("Remote wins: ", $remote)
,
jam:end("local"),
jam:end("remote")
jam:unset() & jam:unset-in()
The jam:unset() function removes the named variable from the remote context. It's not often needed, but handy once in a while. Interestingly, it provides a capability not possible in regular Java! To demonstrate, the following returns (), the default for an unbound variable:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:set("x", xdmp:random()),
jam:unset("x"),
jam:get("x"),
jam:end()
The alternate form jam:unset-in() unassigns the variable in the named context.
jam:get-stdout() & jam:get-stdout-in()
The jam:get-stdout() function returns an xs:string holding the content that's been written to standard out in the remote Java context. Each call clears the buffer. For efficiency reasons only the last 10k of content gets retained. This function proves most useful when debugging.
Note that MLJAM only captures output by the BeanShell print() function, not System.out.println(), due to BeanShell limitations. Here's an example:
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:eval('
print("The time is now: ");
print(System.currentTimeMillis());
'),
jam:get-stdout(),
jam:end()
The above query returns the xs:string:
"The time is now: 1147140123010 ".
OK, technically it returns the sequence:
( (), (), "The time is now: 1147140123010 ", () )
But that gets normalized down to just the string value.
jam:get-stderr() & jam:get-stderr-in()
The jam:get-stderr() function operates just like jam:get-stdout() except it returns standard error output written using BeanShell's error() function. It too, due to BeanShell limitations, can't capture System.err.println() output. The jam:get-stdout-in() and jam:get-stderr-in() functions do what, by now, you naturally expect.
jam:source() & jam:source-in()
The jam:source() function loads the named BeanShell source file, useful for loading useful functions or data into the BeanShell context. Beware that the source file path is based on the server filesystem, not the client's. Also beware that windows paths must begin with the drive letter. To demonstrate, the following example shows how a loadme.bsh on the server could expose a new function for the client to call:
jam:start("http://localhost:8080", "mljam", "secret"),
jam:source("c:\packages\beanshell-2.0b4\loadme.bsh"),
jam:eval('
greatnewcall("The loadme.bsh provided this new call");
'),
jam:end()
Using the jam:source() function supports an architecture where numerous, possibly scattered, XQuery clients can each load the same .bsh file on the server and gain access to its functions without having to ever see (or maintain) its source code.
jam:end() & jam:end-in()
Always last, but definitely not least, we have the jam:end() function. This function is how you should end all your MLJAM interactions, unless you specifically want the remote Java context to persist for later use. Calling jam:end() allows the server to garbage collect the resources held by the context. If you forget, the server does run periodic sweeps to end contexts that haven't been touched within a period of time. However, for any context that consumes a large amount of memory (by doing anything with long strings or binary nodes) calling jam:end() should be considered mandatory.
Sample Applications
The best way to learn a library is by seeing it in action, so let's take a quick tour of some practical functions built with MLJAM. Each of these comes from the jam-utils.xqy module distributed along with MLJAM.
You'll notice in the examples we never call jam:start() or jam:end(). In jam-utils.xqy we expect the caller of the function to perform the setup and tear down. That way the library can remain decoupled from the web service address it actually connects to (and as a bonus the same setup can apply to a long series of functions).
Extracting Metadata from a JPEG
Our first example returns the metadata held within the given image. It returns an XML <metadata> root element holding <directory> elements each of which holds numerous <tag> elements. For example:
<exif>
<metadata>
<directory name="Exif">
<tag name="Make">Canon</tag>
<tag name="Model">Canon EOS D30</tag>
<tag name="Date/Time">2002:07:04 19:02:52</tag>
...
</directory>
<directory name="Canon Makernote">
<tag name="Macro Mode">Normal</tag>
<tag name="Self Timer Delay">Self timer not used</tag>
<tag name="Focus Mode">One-shot</tag>
...
</directory>
<directory name="Jpeg">
<tag name="Data Precision">8 bits</tag>
<tag name="Image Height">1080 pixels</tag>
<tag name="Image Width">720 pixels</tag>
...
</directory>
</metadata>
</exif>
The code, shown below, uses the public domain com.drew.metadata Java library available from http://www.drewnoakes.com/code/exif/ (and also distributed with MLJAM).
define function jamu:get-jpeg-metadata($img as binary()) as element(metadata)
{
jam:set("exifimg", $img),
jam:eval-get('{
import com.drew.metadata.*;
import com.drew.metadata.exif.*;
import com.drew.imaging.jpeg.*;
import org.jdom.Element;
import java.util.*;
InputStream in = new ByteArrayInputStream(exifimg);
Metadata jmr = JpegMetadataReader.readMetadata(in);
Iterator directories = jmr.getDirectoryIterator();
Element exif = new Element("metadata");
while (directories.hasNext()) {
Directory directory = (Directory)directories.next();
Element dir = new Element("directory");
dir.setAttribute("name", directory.getName());
exif.addContent(dir);
Iterator tags = directory.getTagIterator();
while (tags.hasNext()) {
Tag tag = (Tag)tags.next();
Element t = new Element("tag");
dir.addContent(t);
t.setAttribute("name", tag.getTagName());
t.setText(tag.getDescription());
}
}
exif; // return this
}')
}
The first line uses jam:set() to send the binary() image to the server as the "exifimg" variable. Per the jam:set() type mapping, an XQuery binary() node becomes a Java byte[].
The remainder of the function executes Java code that loops over the "directories" held within the image and builds from the directories a JDOM structure. Because the function invoked the Java code using jam:eval-get() it can retrieve the value from the last statement, which in this case is the "exif" variable, a JDOM Element. The jam:get() type mapping dictates a JDOM Element becomes an element() node when received by XQuery.
We surround the code using single quotes. That way the double quotes within the Java don't cause problems. We surround the code with curly braces so that it runs as an isolated Java code block, and that limits the scope of the variables created within.
Applying an XSLT Stylesheet
Our next example applies an XSLT stylesheet against a passed-in node and returns the result as a document.
Editor's Note: MarkLogic has supported XSLT since MarkLogic 5.
define function jamu:xslt-sheet($node as node(), $sheet as element())
as document-node()
{
jam:set("xsltnode", $node),
jam:set("xsltsheet", $sheet),
let $retval :=
jam:eval-get('{
import javax.xml.transform.*;
import javax.xml.transform.stream.StreamSource;
import javax.xml.transform.stream.StreamResult;
Templates templates =
TransformerFactory.newInstance().newTemplates(
new StreamSource(
new StringReader(xsltsheet)));
StreamSource source = new StreamSource(
new StringReader(xsltnode));
ByteArrayOutputStream baos = new ByteArrayOutputStream(10240);
StreamResult result = new StreamResult(baos);
templates.newTransformer().transform(source, result);
baos.toByteArray(); // return this
}')
return xdmp:unquote(xdmp:quote($retval))
}
The processing takes place in the remote Java context using Java's JAXP and TrAX libraries. The code follows the common pattern: the function first passes its function parameters to the Java context (XQuery nodes become Java Strings), then runs a jam:eval-get() call to execute Java code and fetch the value of the last statement as the result. The result in this case is a byte[], visible to XQuery as a binary() node. Now, we want to return a document-node(), not a binary(), so we do a little quote/unquote work on it to convert the binary() to a string, then to a document-node().
When using this function, it's best to have the stylesheet dictate <xsl:output method="xml" encoding="UTF-8"/> so that JAXP knows the results should be XML not HTML. Also, remember that because the stylesheet is passed in as an argument itself, the sheet won't be able to resolve external resources. This could be fixed with a version that ran from a file on the server, for example.
Generating a PDF
The last example we'll look at here (there are more in jam-utils.xqy) accepts an XSL-FO element and returns a generated PDF document built using the new Apache FOP 0.92.
define function jamu:fop($xslfo as element()) as binary()
{
jam:set("xslfo", $xslfo),
jam:eval-get('{
import org.apache.fop.apps.*;
import javax.xml.transform.*;
import javax.xml.transform.sax.SAXResult;
import javax.xml.transform.stream.StreamSource;
import org.xml.sax.*;
Transformer trans = TransformerFactory.newInstance().newTransformer();
Source source = new StreamSource(new StringReader(xslfo));
FopFactory fopFactory = FopFactory.newInstance();
ByteArrayOutputStream baos = new ByteArrayOutputStream(10240);
Fop fop = fopFactory.newFop(MimeConstants.MIME_PDF, baos);
Result res = new SAXResult(fop.getDefaultHandler());
trans.transform(source, res);
baos.toByteArray(); // return this
}')
}
This code looks a lot like the previous example because FOP does all its work with TrAX. The difference: it uses FOP's DefaultHandler to receive the SAX events and produce a PDF captured to the ByteArrayOutputStream. That byte[] comes back to XQuery as a binary(), and that's a perfect holder for our PDF.
An Enhanced Position for XQuery
At the lowest-level, the MLJAM library gives XQuery a little muscle it wouldn't otherwise have. It provides a vehicle for the manipulation of binaries (which XQuery isn't very good at), and makes even String, numeric, or XML manipulation easier when the task is complicated and there's a pre-existing Java library practically begging to be used (witness XSLT transformations or MD5 hashing).
At a higher-level, however, the MLJAM library (in conjunction with MLSQL) may enhance the position XQuery holds in MarkLogic Server web application architectures. (Bear in mind this is only the personal opinion of the authors.)
There's probably a 50/50 split right now in customer projects that use XQuery as the primary web page scripting language and those that use Java or .NET as primary (and use XDBC/XCC to drive the XQuery).
The customers who choose XQuery generally do so because it enables rapid and agile development. It's a beautiful thing when the language of the web page (XQuery) perfectly matches the language of the back-end (XML), and natively understands the language of the front-end to boot (XHTML). Without an impedence mismatch on either the front or back end, development chugs along quickly.
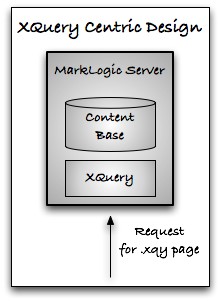
The customers who choose Java/.NET sometimes do it because it fits into their existing J2EE or .NET stack. For these customers there will be no change. They need to use XDBC (now XCC) to drive XQuery from Java or .NET.
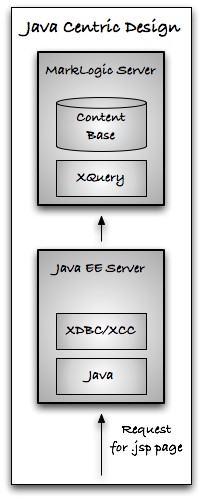
However, some customers have had the desire to use XQuery as the primary web page language, but haven't felt they had the option. They've had requirements that a pure XQuery web framework couldn't handle alone -- credit card billing, relational database integration, PDF generation -- exactly the things that XQuery can now control via MLJAM and MLSQL.
This is why we (Jason and Ryan) wrote the libraries. We have projects like this. Instead of Java driving XQuery, we want XQuery to drive Java. We want the option to use XQuery as a primary web page language, with its simpler and more agile architecture, but keep the ability to access into Java or a relational system when something's better done there. In this model, XQuery becomes the glue language: for querying and manipulating XML managed by MarkLogic, for rendering XHTML web pages or PDF documents, for easy integration with a relational system, or for a quick call into Java to do something special.
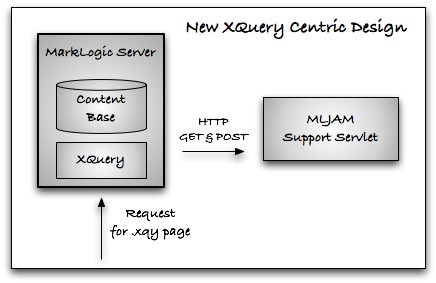
Installation and Security
Installing MLJAM requires a few simple steps:
First, expose the jam.xqy library module to your XQuery code. This usually requires copying the file into your HTTP server root directory, but depending on configuration might require loading into the server's modules database. You may want to install jam-utils.xqy while you're at it so you can take advantage of that set of pre-defined utility functions.
Second, install the servlet code. The distribution includes a build directory containing the web application root. Copy this to your servlet engine's webapps directory or adjust the server's configuration to point at the directory as a web application root. (If you don't have a servlet engine, Jetty is an free server that's easy to install and configure.)
Important: If you install MLJAM in the webapps directory as .../webapps/mljam then your access URL will need to be http://localhost:8080/mljam/mljam. The first /mljam is the application context path; the second is the servlet name. The examples in this tutorial use http://localhost:8080/mljam which assumes MLJAM gets installed in the root context so the first /mljam isn't necessary.
Third, configure security. By default the servlet responds to anyone who makes a connection. You can and should restrict this in three ways. First, a tool like tcpwrappers can ensure connections are only accepted from specific hosts (like localhost). Second, you can configure the servlet to require login credentials. The second half of the web.xml file includes a commented out section that enables security by restricting access to users in the mljam role. You'll need to uncomment this and create a user with the mljam role in your web server. Exactly how to do that varies by web server. Third, you can configure the Java servlet to operate under a security policy that restricts what actions the BeanShell code can perform. You can remove its ability to access the filesystem or invoke other programs, for example. See http://tomcat.apache.org/tomcat-5.0-doc/security-manager-howto.html for a discussion on how to configure Tomcat 5 with a restrictive security policy.
Fourth, test the servlet's URL. Try making a basic web request to the MLJAM servlet. The URL will be something like http://localhost:8080/mljam/... depending on where and how your servlet engine is configured. You'll know it's listening when a request like http://localhost:8080/mljam/123/get?name=mljamid returns the context id "123" (mljamid is a special variable used by the context to remember its name). The context will be created automatically on first use.
Fifth, try a basic query:
import module namespace jam = "http://xqdev.com/jam"
at "jam.xqy"
jam:start("http://localhost:8080/mljam", "mljam", "secret"),
jam:eval-get("1+1"),
jam:end()
You might need to adjust the "at" depending on where you placed the library module. If it prints 2 you've got a successful install.
Now have fun!
Performance
How fast does MLJAM operate? It depends of course on your system. On a three-year-old midrange laptop, connecting locally between MarkLogic Server and the MLJAM servlet running under Tomcat 5, we've seen latency times of 10ms. Sustained transfer speeds vary depend on the type of content and direction of communication. String content moves at about 5 Megabytes per second between the servers. Binaries move much faster from the servlet to MarkLogic, up to 20 Megabytes per second, because there's very little overhead. However, binaries move significantly slower from MarkLogic to the servlet -- approximately 2 Megabytes per second -- because xdmp:http-post() doesn't allow for pure binary() POST bodies and the binary nodes have to be hex encoded for sending and then decoded in Java.
Within the servlet, the BeanShell code execution speed will be a little slower than usual Java (due to parsing overhead), but as soon as the BeanShell code calls into JAR code the speed should exactly match a regular Java program.
We've seen Java performance improve over time on long running servers. That's probably because on a long running process the HotSpot JVM can optimize the heavily used code paths.
The wire protocol for MLJAM is documented in an accompanying article MLJAM: Wire Protocol Documentation.