What It Is
The revolutionary Optic API blends the relational world with rich NoSQL document features by providing the capability to perform joins and aggregates over documents. One of the enabling features, Template Driven Extraction, makes it possible to create a relational lens over documents stored in MarkLogic by using templates to specify the parts of a document that make up a row in a view. You can access that data using either SQL or the Optic API.
The Optic API uses row, triple, and/or lexicon lenses over documents, and is powered by the new row index. With the Optic API, you can use full-text document search as a filter, perform row operations to join and aggregate data, and retrieve or construct documents on output. It's available in all of MarkLogic's supported languages: JavaScript, XQuery, REST, Java, and soon Node.js. Each implementation adopts language-specific patterns so it feels conceptually familiar if you have relational experience and syntactically natural given your existing programming knowledge.
Here is an example query using the Optic API in JavaScript:
Why It Matters
The MarkLogic Optic API makes it possible to perform powerful NoSQL joins and aggregates across documents. Developers can use document search to retrieve rows projected from documents, join documents as columns within rows, and construct document structures dynamically — all performed efficiently within the database and accessed programmatically from your application.
NoSQL databases bias towards denormalization of data, where documents represent real world entities. This data model supports development and search — all information about an entity is conveniently in one place for efficient retrieval and update. But in some cases your entities are naturally in normalized form and it is better to keep them that way. Or, your questions rely on the relationships across entities. The flexible Optic API allows you to use your data as-is, producing denormalized data on read for use in your applications. The API makes it possible to harness the full power of MarkLogic's document and search capabilities using familiar syntax, incorporating common SQL concepts, regardless of the underlying shape of your data.
XQuery and JavaScript Examples
Environment Setup
For the examples in this section you need MarkLogic 9 installed and configured. See the Installation Procedures if you have not previously done this step.
Sample queries use data from the Samplestack project. You can use Samplestack's provided gradle scripts to secure and load the database.
To make use of Samplestack's set up process:
- Make sure you have git and Java 8 installed and on your path
- Run
git clone https://github.com/marklogic/marklogic-samplestack cd marklogic-sampletack/appserver/java-spring- Create and configure the database by running
./gradlew assemble(it's okay if some of the tests fail; note that you must have port 8006 free before setting up Samplestack) - Load the data set using
./gradlew dbload
By default this process will secure MarkLogic with the username admin, password admin. If you have already secured MarkLogic, modify appserver/java-spring/gradle.properties before running the gradle scripts using your own admin credentials.
Alternatively, you can view and load the raw data yourself.
Example 0 -- Templates for Samplestack Data
We'll start by surfacing key information from our data set by creating templates. Template Driven Extraction (TDE) indexes documents as-is in the row index for scalable aggregates and joins. Read more about template driven extraction for details on laying a relational lens over your data for use in the Optic API.
Samplestack seed data comes from Stack Overflow. The data set consists of two types of JSON documents, which are modeled on real-world entities and activities:
- One type of document represents Question and Answer discussion threads (sample QnA doc)
- The other document type represents those who contribute to QnA threads by asking and answering questions, like a user profile (sample Contributor doc)

There can be a many-to-many relationship between QnA and Contributor documents. The document data model is well suited to Samplestack, which prioritizes searchability, so users can find the QnA thread most relevant to their needs. The application also supports updates, and the flexible document model easily adapts to capture additional answers, comments, or other data that might later be part of a QnA thread.
By putting key fields, like User Reputation, into the row index, we're adding a relational lens over our documents. For example, we can quickly aggregate Reputation across Users. Data in rows can also be efficiently joined with other distributed, yet related, data -- such as QnA threads where the Users participate.
Template Driven Extraction
The included examples make use of a few different views. Open Query Console to define lenses over the sample data. Download and import the Samplestack-TDE workspace and follow the instructions to load the templates.
Use JavaScript to Load User template:
Follow the same process to load QnA, Answer, and QTag templates by running the included tabs. Using tde.templateInsert will upload the provided template to the Schemas database with the tde collection and automatically trigger population of the row index based on content in MarkLogic. In the provided workspace you'll also find a couple of tabs to validate and explore the views created over your documents. Here is a look at the three relational lenses we are using over our two Samplestack document types:
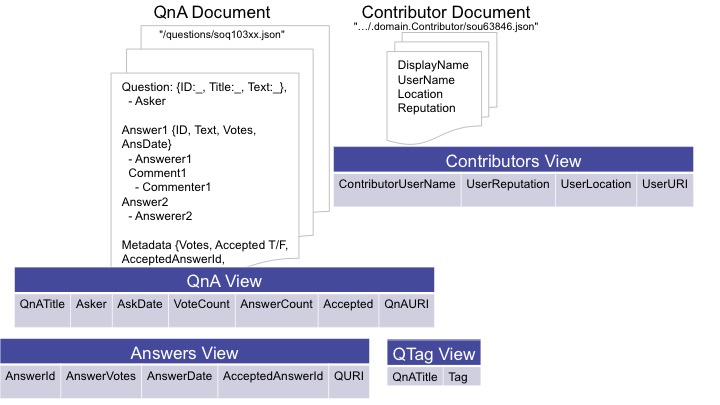
Now it's time to use the Optic API to query the data with the exposed relational lenses. For the best experience, use the language driver you are most comfortable with:
- The MarkLogic Java Client API supports Optic query construction and row result processing -- see detailed Java Optic examples here.
- In the following section you will find a detailed overview of the Server-side JavaScript interface.
- XQuery Examples are available at the bottom of the current page.
- The REST API supports Optic queries and is great for those who want to build their own language wrappers. See REST API Examples farther down the page for tips on getting started.
Example 1 -- Row Query
To explore the Optic API's capabilities, you can paste these examples into Query Console. Choose "JavaScript" or "XQuery" as the query type and use the "samplestack" database.
Begin using the Optic API by performing a basic query on a view over documents. Querying the view will return rows. Run the following in Query Console to Query User Rows:.
That's it! You've just retrieved your first row set. In Query Console, you can choose to view your results as a SQL table, JSON, or text. As JSON, your results should look something like this:
In this example, a query is constructed to return rows fromView "Contributors", in the "Samplestack" schema. It is specifically retrieving the columns ContributorUserName, UserReputation, and UserLocation. Resulting columns are qualified by "SchemaName.ViewName".
Additional functions modify the result set, and should look familiar to those with SQL experience:
orderBysorts the row results by the UserReputation columnwherefilters the results to rows where the UserReputation column is greater than the specified minimum reputation levellimitconstrains the number of rows returned (to 25 in this case)
The final step is to execute the query using result. Until this point you are only building the query plan.
Note the import of the /MarkLogic/optic JavaScript library at the beginning of the code sample, using the convention op.
The SQL equivalent for this query is provided for reference:
You will notice the names and purposes of the Optic API operations are familiar from SQL, but have the benefit of language integration. Not only is the idiomatic, chainable function style familiar to JavaScript programmers, but the ability to incorporate variables makes data retrieval a safer, smoother experience. The use of the minRep constant in this example demonstrates the benefits of using the Optic API over using Common Table Expressions and string concatenation to submit a SQL query from JavaScript.
Take a minute to explore the other included Query tab to Query QnA Rows.
In these basic examples, each of the rows returned is contained within a single document. The following examples introduce increasingly more powerful capabilities, including the opportunity to return rows that span documents.
Example 2 – Aggregates and Grouping
Use the MarkLogic Optic API to conveniently perform aggregate functions on values across documents. In this example, several operations are performed to get a sense of basic statistics about the Samplestack User data. Run the following query to aggregate user stats:
The first parameter in the groupBy is empty to groupBy all rows. A set of aggregates are defined to count the users, calculate the minimum/maximum/average values for Reputation, and compute the fraction of users who have specified a location in their profile. All of these aggregate functions are in the Optic library and the operations must be qualified. In the select statement, further processing is done to format the output: average reputation is truncated and the location fraction is displayed as a percentage. The Optic API has access to MarkLogic’s other function libraries such as math and fn. Calls to built-in libraries must be prefixed using the convention op so calls are deferred and executed with the rest of the query plan as optimized by the engine. When passing column values to built-in libraries as parameters, use the col identifier, especially to distinguish from strings.
The next query performs similar operations in order to aggregate QnA stats. One difference from the previous query is that a grouping parameter – column name ‘Accepted’ – is applied to the groupBy statement to separate summary statistics for questions that have an accepted answer from those questions that do not have an accepted answer.
Example 3 – Row Joins
This example joins Question & Answer information with related user data to return a richer result. That is, more data elements (columns) are returned than are stored in the QnA document itself – this is denormalized data-on-read, in action!
Run the following query to join rows in order to answer the question, "What is the reputation of the asker for the highest voted questions?":
The questions (QnA) view is joined with the users (Contributors) view on user name – which is called "Asker" and "ContributorUserName" in the respective source views. This value is used as a key to join related information. The inner join yields one output row set that concatenates one left row and one right row for each match between the keys in the left and right row sets. An inner join is a type of filter. If there is no user profile row corresponding to the question document, fewer than 10 results will be returned.
The Optic API is purposefully flexible about the ability to specify the sequence and frequency of operations. orderBy is deliberately used twice in this example. Because we are only interested in the 10 most voted questions, we can filter (order+limit) so we only join on the rows of interest. Because relational joins are not guaranteed to preserve order, we sort the final output. desc specifies the sort order.
SQL to Optic 101
List available tables
Almost all activities with a database start with exploration of what tables are available and how those tables look like.
Here's an example of that activity in SQL:
There is currently no direct counterpart for displaying the columns of a table. But the below query will provide a good background regarding available views:
Explore sample records
In SQL:
Using Optic API:
The sample result would be as follows:

In JSON:
Hrm… what if I want those column names to be the key? That is, without the schema and table prefix. I don’t really want my client to keep handling the schema and table names with each request.
Using Optic API:
Resulting in:

In JSON:
Now that we have some basic syntax going, let’s explore the data some more.
Some basic queries
In SQL:
Using Optic API:
The sample result would be:

Some things that are worth noting above:
- We need to specify fields using 'op:col' (or equivalent: 'op:view-col', 'op:schema-col') on where clauses.
- Select clauses can use 'op:col' or simple string that matches the view’s columns.
- Column names, when used on the various clauses are case insensitive. But the result will always use character case as specified in the template by default.
Multiple and grouped queries
In SQL:
Using Optic API:
The sample result would be:

Now that we have a good grasp of our data, let’s try something a little bit more challenging. Let’s try to look for the top 'asker' per month.
Function on queries
In SQL:
Using Optic API:
The above query makes use of supported functions in MarkLogic. The list of supported SQL functions is available here while the list of supported Optic API functions is available here. It is required to import the respective functions as needed, e.g.:
Let’s limit this to those having more than 10 questions.
In SQL:
Using Optic API:
It is important to note that the 'where' clause appears after the 'group by' clause. The earlier clause (modify plan) will dictate the data (row set) available to the succeeding clause, i.e.:
The above will not work since 'qaskdate' is no longer part of the rowset specified by the 'group-by' modifier. To limit the result to a particular constraint, the query would have to be adjusted as follows:
All the columns of 'samplestack.qna' are available to the initial 'where' plan modifier and the succeeding 'group-by' plan modifier.
Sub-queries
But how do I now limit the count to users that come from 'London'?
Unfortunately such queries cannot be directly ported to Optic API. What we can do is to adjust the approach.
In SQL:
Using Optic API:
Going beƒyond just SQL
One major limitation of SQL is the inability to search for a particular word across all fields. Optic API supports use of 'cts:query' objects to be used in the 'where' modifier:

It is important to note though, that this word search will apply to the entire document and not just the fields involved in the view.
Information about the source document is also available to be part of the response:

Optic API is not limited to views. We can also make use of existing indexes. Referencing the data we have in this article, we can now produce the same result using with and without the Optic API.
XQuery without Optic API:
Using Optic API:
This example makes use of the URI lexicon:
