Analytics
"Analytics" is used to describe a class of functionality in MarkLogic that relates to retrieving values and frequencies of values across a large number of documents. With search/query, we're interested in finding documents themselves. With analytics, we're interested in extracting all the unique values that appear within a particular context (such as an XML element or JSON key), as well as the number of times each value occurs. An example of analytics in a MarkLogic application is the message traffic chart on MarkMail.org:
![Machine generated alternative text: 0 0 0 Home - MarkMaiI - Commt (- C [markmail.org s I ]UIM[ark Ìt o- Want your own MarkMair? Tell us about it. Sign In or Sign Up (Why?) Summary of all Messages What’s New Search for: T (_Search_J ç Actions > Previous news itE > Subscribe to the > Read the FAQ > Give feedback > Advertise here > 1 FINDMEOII-’1 I ¡‘‘‘ ‘- I I._ ) About MarkMall harmony mozilia spamassassin Who invoked Godwin’s Law? MarkMaiI is devel apache hibernate myfaces squid-cache MarkLogic Corpor cocoon httpd mysal struts “godwin’s law” opt:noquote MarkMail is a free s incubator pj thunderbird mailing list archives discuss advantages over tr jdom p.jj tomcat engines. It is power fìrfrw jri.h, nhñ Searches for these SDeclfies that tte Server: Each email](/media/marklogic-for-java-developers_files/screenshot25.jpg)
The above chart portrays ranges of email message dates bucketed by month, as well as the number of messages that appear each month. Since MarkMail hosts over 50 million messages, it of course does not go read all those messages when you load the page. Instead, whenever a new document (email message) is loaded into the database, its date is added to a sorted, in-memory list of message dates (values), each associated with a count (frequency). This is achieved through an administrator-defined index (called a range index).
A range index is one kind of lexicon. Whenever you want to perform analytics, you need to have a lexicon configured. In addition to range indexes, other lexicons include the URI lexicon and the collection lexicon. Each of these must be explicitly configured in the database.
Retrieve all collection tags
For this example, you need to have the collection lexicon enabled. Fortunately, we already took care of that at the beginning when we set up the database. Open Example_33_ValuesOfCollectionTags.java. As when defining constraints, we need a QueryOptionsBuilder for making values available, this time with the withValues() method:
The first argument to values() is the name we'll be using when we fetch the values ("tag"); the second defines the source of those values. The collection() constructor indicates the collection lexicon as the source. Next we upload the options to the server for our subsequent use, just as we did in the constraint examples:
Whereas with a search we need to construct a QueryDefinition, with a values retrieval we need to construct a ValuesDefinition, passing it both the name we defined ("tag") and the name of the options we just configured on the server:
Similarly, whereas with search we use a SearchHandle to receive results, with values we use a ValuesHandle to receive the results:
The above line defines the handle and fetches the results in one step. This time, instead of calling search(), we call our query manager's values() method. Now we'll print out the results using the handle's getValues() accessor:
Run the program. The output shows all the collection tags and their frequency of usage (in other words, how many documents are in each collection). You can also view the values directly in your browser at: http://localhost:8011/v1/values/tag?options=Example_33_ValuesOfCollectionTags.
Retrieve all document URIs
This example requires the URI lexicon to be enabled. Starting in MarkLogic 6, it's enabled by default, so here too we're ready to go. Open Example_34_ValuesOfURI.java. This example is almost identical to the previous one except that we're choosing a different values name ("uri") and a different values source (the URI lexicon):
Theuri() constructor indicates the URI lexicon as the source. Run the program to see all the document URIs in the database, as well as how many documents they're each associated with (the frequency). For all the JSON and XML document URIs, the answer of course is just one per document. But you might be surprised to see that each image document URI yields a count of 2. That's because each image document has an associated properties document which shares the same URI.
Set up some range indexes
Before we can run the remaining examples in this section, we need to enable some range indexes in our database. Since we have a small number of documents, it won't take long for MarkLogic to re-index everything. At a much larger scale, you'd want to be careful about what indexes you enable and when you enable them. That's why such changes require database administrator access.
We're going to set up the following range indexes:
| scalar type | namespace uri | localname |
|---|---|---|
| string | empty | SPEAKER |
| string | http://marklogic.com/xdmp/json/basic | affiliation |
| int | http://marklogic.com/xdmp/json/basic | contentRating |
| unsignedLong | http://marklogic.com/filter | size |
| string | http://marklogic.com/filter | Exposure_Time |
Navigate to your database's configuration page for element range indexes (at http://localhost:8001/):
![Machine generated alternative text: [] Configure ! Groups iL Databases IFIS App-Services E}I Documents Extensions EF Fab E}i Last-Login Modules LEF Security EI Tnggers $Ctona1DB ¡ Ei[ Forests I I E Flexible Replication ! ! Database Replication I Ei Fragment Roots ¡ EI Fragment Parents I EF Triggers ! ! Merge Policy I E Scheduled Backups ¡ EI Content Processin I I a Element Range Indexes ! ! Ifl Attribute Range Indexes ! Field Range Indexes](/media/marklogic-for-java-developers_files/screenshot26.jpg)
At the top of the page, click the "Add" tab:

Here you will enter the appropriate values for one range index. We'll be concerned with just three form fields (leaving the rest at their defaults):
- scalar type
- namespace uri
- localname
For example, to configure the first range index, you'd choose "string" for scalar type, leave the namespace uri field blank, type "SPEAKER" for localname, and hit "OK":
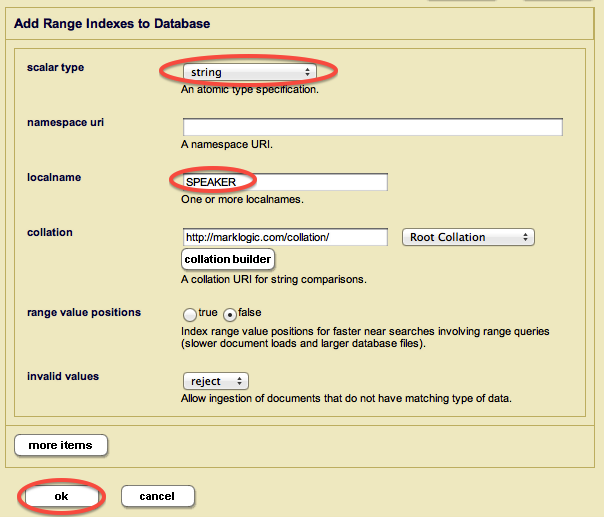
This will cause the database to build a range index on all <SPEAKER> elements. Using the same process described above, add each of the remaining range indexes to your database:
| scalar type | namespace uri | localname |
|---|---|---|
| string | http://marklogic.com/xdmp/json/basic | affiliation |
| int | http://marklogic.com/xdmp/json/basic | contentRating |
| unsignedLong | http://marklogic.com/filter | size |
| string | http://marklogic.com/filter | Exposure_Time |
Now that we have the indexes configured, let's dive back into Eclipse.
Retrieve values of a JSON key
Open up Example_35_ValuesOfJSONKey.java. First we initialize our query options with a values spec:
As with collection and URI values, we start by choosing a name ("company"). This time, instead of uri() or collection(), we use range() to indicate that a range index is the source of the values. Here we must make sure that the arguments we pass exactly line up with the range index that's configured in the database. Otherwise, you'll get an "index not found" error when you try to retrieve the values.
You may recall that we used a jsonTermIndex() to indicate the source of a key constraint. A "term index" is always enabled as part of MarkLogic's Universal Index and lets you lookup documents based on some criterion. In this case, we want to retrieve all the values of a given JSON key (rather than find a document, given its key). For that, we need to use the range index and thus we call jsonRangeIndex(), passing it the name of the key and the type of the indexed values (string, using the default collation).
The last thing to point out above is that, rather than return the values in alphabetical (collation) order, we want to get them in "frequency order." In other words, return the most commonly mentioned companies first. That's what the "frequency-order" option (passed to values()) lets you do.
Just as with the two previous examples, we create a values definition (using the name "company") and pass it to our query manager's values() method to retrieve the results:
Run the program to see the results. Unsurprisingly, you'll see that MarkLogic was the most common company affiliation at the MarkLogic World conference.
Retrieve values of an element
Open up Example_36_ValuesOfElement.java. Here, rather than using a jsonRangeIndex(), we're using an elementRangeIndex() to indicate the source of our "speaker" values:
Run the program to see all the unique speakers in the Shakespeare plays, starting with the most garrulous.
Compute aggregates on values
Not only can we retrieve values and their frequencies; we can also perform aggregate math on the server. MarkLogic provides a series of built-in aggregate functions such as avg, max, count, and covariance, as well as the ability to construct user-defined functions (UDFs) in C++ for close-to-the-database computations.
Open up Example_37_ValuesOfJSONKeyNumeric.java. In this example, we're going to access an integer index on the "contentRating" JSON key:
This time, in addition to setting up the values definition, we'll configure it to compute both the mean and median averages:
Before fetching the values, we'll opt to get them in descending order (highest ratings first):
Run the program to see how many conference talks scored 5 stars, how many scored 4 stars, etc.—as well as the mean and median rating for all conference talks.
Constrain the values returned using a query
This example starts to hint at the real power of MarkLogic: combining analytics with search. Rather than retrieve all the values of a given key, we're going to retrieve only the values from documents meeting a certain criterion. In this case, we'll get all the ratings for conference talks given by employees of a certain organization. To configure this, we supply both a values option and a constraint option:
In a nutshell, the above configures two things: a "rating" lexicon and a "company" constraint. To retrieve values, we define the values definition as usual, but this time we also associate it with a query, using the setQueryDefinition() method:
Run the program to see the ratings of all talks given by MarkLogic employees (documents matching the "company:marklogic" string query). You can also see these results in the browser using this URL: http://localhost:8011/v1/values/rating?options=Example_38_ValuesWithQuery&q=company:marklogic&format=json
Retrieving tuples of values (co-occurrences)
In addition to retrieving values from a single source, you can also retrieve co-occurrences of values from n sources. In other words, you can perform analytics on multi-dimensional data sets. Open up Example_39_Tuples.java. In this case, we're getting all the unique pairings of photo size and exposure time, via the withTuples() method:
The tupleSources() constructor takes two value sources. In this case, we're accessing two range indexes. Like a call to values, we start with a ValuesDefinition, giving it the name we configured ("size-exposure"), but then we call tuples() to fetch the tuples:
Also, instead of a ValuesHandle, we use a TuplesHandle, which encapsulates the data in a POJO through which we can access each tuple using getTuples():
Searching with facets
As mentioned earlier, MarkLogic's real power lies in the combination of search and analytics. A couple examples ago we saw how a query could be used to constrain a values retrieval. What we haven't seen yet is how the query manager's search() method can also return lists of values (called "facet values") along with its search results. These facets can then be used to interactively explore your data. In this case, we're not calling values() at all, just search.
But before we can run a faceted search, we need to define one or more constraints that are backed by a lexicon or range index. See in Example_40_SearchWithFacets.java:
The above configuration makes the "rating" and "company" constraints available for users to type in their query search string. You may be thinking "Isn't that only going to be useful for power users? Most users aren't going to bother learning a search grammar." That's true, but with a UI that supports faceted navigation, they won't need to. All they'll have to do is click a link to get the results constrained by a particular value. For example, the screenshot below from MarkMail shows four facets: month, list, sender, and attachment type:
![Machine generated alternative text: MarkM1it j) Home Messages per 12000C 100000 80000 60000 20000 ‘00 .01 ‘02 ‘03 ‘04 ‘05 ‘06 ‘07 jWhat List? . netjava.dev.opensso.issues netjava,dev.glassfish.users net.java.dev.maven-repository.cvs org .jboss.I ists.jboss-cvs-commits org.netbeans.nbusers netjava.dev.glassfish.issues org .j boss.I ists.jboss-user org.apache.tuscany.dev netjava.dev.mojarra.commits netjavadev.mifosissues netjava.dev.sailrinissues net.java.dev.hudson.users orgapache.hadoop.core-dev com.googlegroups.google-web-toolkit Month Remove date refinements’ tir. ‘08 ‘09 ‘10 ‘11 12 View morel 9,034 8,095 7,282 6,767 6,079 5,503 5,188 5,097 5,004 4,721 4,686 4,665 4,467 4,278 ‘Who Sent It? View more LS’] Attachments? View moro kohs,..©dev.java.net 7,321 patch 980 mave..©dev.java.net 7,280 zip 858 rlu.,cdev.java.net 6,741 txt 713 jbos...©lists.jboss.org 6,270 jpg 686 glas..javadesktop.org 5,725 java 578 Continuum VMBuild Server 4,334 gif 466 Build Daemon user 3,428 png 445 sv...©wso2.org 3,343 log 437 met...©javadesktop.org 3,139 html 393 cont..©apache.org 2,888 duff 353 to...©freenetprojectorg 2,718 xml 335 jbos...lists.jboss.org 2,541 pdf 236 dcleal 2,529 dat 208 code...tgoogle.com 2,454 Other 201](/media/marklogic-for-java-developers_files/screenshot29.jpg)
Each of these is a facet, whose values are retrieved from a range index. Moreover, users can drill down and pick various combinations of facets simply by clicking a link, or in the case of the histogram, swiping their mouse pointer.
MarkLogic's Java API gives you everything you need to construct a model for faceted navigation. Our sample program doesn't include a UI, but it will run a series of searches that a user might have chosen:
For each of the above search strings, we run the search and print out all the facets and their values:
Run the program to see the results.
Just as the API provides a model for a list of search results (an array of MatchedDocumentSummary instances), it also provides a model for facet results (an array of FacetResult instances). The above code gets the facets using the search handle's getFacetResults() method, iterates through each facet, and for each of its values, prints the value and its count (frequency).
We saw earlier how the API models the search results on this site. Now we can see how it models the facet results. One facet ("Category") is represented by a FacetResult object:
![Machine generated alternative text: CATEGORIES 4.—.- •FacetResult All categorIes [87] J Functìon pages [50) ¿ Userguides[12) Bkg posts [11)](/media/marklogic-for-java-developers_files/screenshot30.jpg)
And its values are modeled by FacetValue objects:
![Machine generated alternative text: CATEGORIES Facet Valuefl All categorIes [87] Functìon pages I Userguides[12) 1](/media/marklogic-for-java-developers_files/screenshot31.jpg)
When a user clicks on one of these values, it takes them to a new automatically constrained search results page. For example, if they click "Blog posts," it will re-run their search with the additional constraint "category:blog".
Custom search
More learning resources